If two transactions don’t touch the same data, they can safely be run in parallel. Concurrency issues (race conditions) only come into play when one transaction reads data that is concurrently modified by another transaction, or when two transactions try to simultaneously modify the same data
Concurrency bugs are hard to find by testing and also difficult to reason about, especially in a large application. For that reason, databases have long tried to hide concurrency issues from application developers by providing transaction isolation
In practice, isolation is unfortunately not that simple. Serializable isolation has a performance cost, and many databases don’t want to pay that price. It’s therefore common for systems to use weaker levels of isolation, which protect against some concurrency issues, but not all. Those levels of isolation can lead to subtle bugs (such as money lost, data corrupted), but they are nevertheless used in practice
1. Read Committed
The most basic level of transaction isolation is read committed. It makes two guarantees:
When reading from the database, you will only see data that has been committed (no dirty reads)
When writing to the database, you will only overwrite data that has been committed (no dirty writes)
Read committed is a very popular isolation level. It is the default setting in Oracle 11g, PostgreSQL, SQL Server 2012, MemSQL, and many other databases
Some databases support an even weaker isolation level called read uncommitted. It prevents dirty writes, but does not prevent dirty reads
1.1 No dirty reads
Imagine a transaction that writes data to the database, the transaction has not yet been committed or aborted, if another transaction can see that uncommitted data, that is called a dirty read
Transactions running at the read committed isolation level must prevent dirty reads. This means that any writes by a transaction become visible at once to others when that transaction commits
1.2 No dirty writes
Imagine two transactions concurrently try to update the same object in a database, we normally assume that the later write overwrites the earlier write. However, if the earlier write is part of a transaction that has not yet committed, so the later write overwrites an uncommitted value, that is called a dirty write
Transactions running at the read committed isolation level must prevent dirty writes, usually by delaying the second write until the first write’s transaction has committed or aborted
1.3 Implementing read committed
Most databases prevent dirty writes by using row-level locks: when a transaction wants to modify a particular object (row or document), it must first acquire a lock on that object. It must then hold that lock until the transaction is committed or aborted. Other transactions who want to write to the same object must wait until the first transaction is committed or aborted before it can acquire the lock and continue. This locking is done automatically by databases in read committed mode (or stronger isolation levels)
Most databases prevent dirty reads using this approach: for every object that is written, the database remembers both the old committed value and the new value set by the transaction that currently holds the write lock. While the transaction is ongoing, any other transactions that read the object are simply given the old value. Only when the new value is committed do transactions switch over to reading the new value
Another option to prevent dirty reads would be to use the same lock, and to require any transaction that wants to read an object to briefly acquire the lock and then release it again immediately after reading. However, the approach does not work well in practice, because one long-running write transaction can force many read-only transactions to wait until the long-running transaction has completed
2. Snapshot Isolation
There are still plenty of ways in which you can have concurrency bugs when using read committed isolation level. This anomaly is called a nonrepeatable read or read skew (timing anomaly). In Alice’s case, this is not a lasting problem, because she will most likely see consistent account balances if she reloads the online banking website a few seconds later. However, some situations cannot tolerate such temporary inconsistency:
Backups: Taking a backup requires making a copy of the entire database, which may take hours on a large database. During the time that the backup process is running, writes will continue to be made to the database. Thus, you could end up with some parts of the backup containing an older version of the data, and other parts containing a newer version. If you need to restore from such a backup, the inconsistencies (such as disappearing money) become permanent
Analytic queries and integrity checks: Sometimes, you may want to run a query that scans over large parts of the database. Such queries are common in analytics, or may be part of a periodic integrity check that everything is in order (monitoring for data corruption). These queries are likely to return nonsensical results if they observe parts of the database at different points in time
Snapshot isolation is the most common solution to this problem. The idea is that each transaction reads from a consistent snapshot of the database—that is, the transaction sees all the data that was committed in the database at the start of the transaction. Even if the data is subsequently changed by another transaction, each transaction sees only the old data from that particular point in time. Snapshot isolation is a boon for long-running, read-only queries such as backups and analytics, and is supported by PostgreSQL, MySQL with the InnoDB storage engine, Oracle, SQL Server, and others
2.1 Implementing snapshot isolation
Implementations of snapshot isolation typically use write locks to prevent dirty writes. However, reads do not require any locks. To implement snapshot isolation, the database must potentially keep several different committed versions of an object, because various in-progress transactions may need to see the state of the database at different points in time. Because it maintains several versions of an object side by side, this technique is known as multi-version concurrency control (MVCC)
Storage engines that support snapshot isolation typically use MVCC for their read committed isolation level as well. A typical approach is that read committed uses a separate snapshot for each query, while snapshot isolation uses the same snapshot for an entire transaction
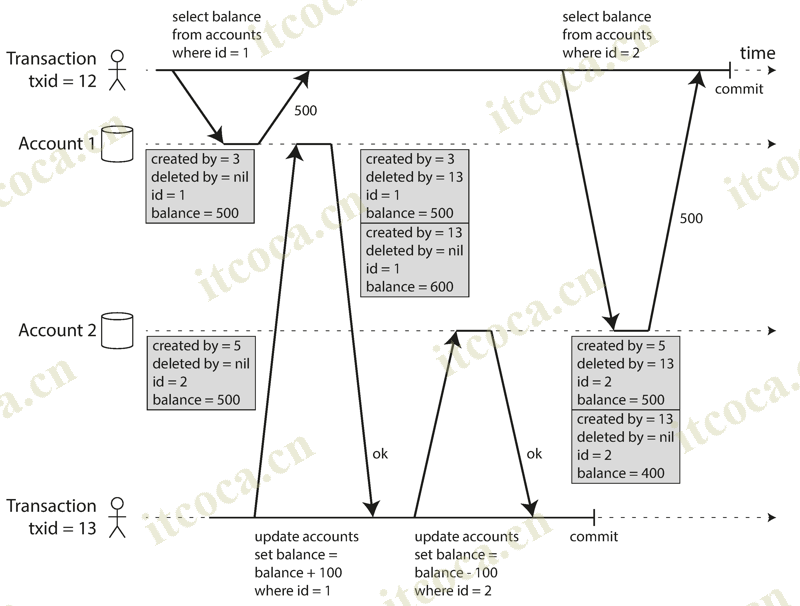
Figure below illustrates how MVCC-based snapshot isolation is implemented in PostgreSQL (other implementations are similar). When a transaction is started, it is given a unique, always-increasing transaction ID (txid). Whenever a transaction writes anything to the database, the data it writes is tagged with the transaction ID of the writer
Each row in a table has a created_by field, containing the ID of the transaction that inserted this row into the table. Moreover, each row also has a deleted_by field, which is initially empty. If a transaction deletes a row, the row isn’t actually deleted from the database, but it is marked for deletion by setting the deleted_by field to the ID of the transaction that requested the deletion. At some later time, when it is certain that no transaction can any longer access the deleted data, a garbage collection process in the database removes any rows marked for deletion and frees their space
An update is internally translated into a delete and a create. For example, transaction 13 deducts $100 from account 2, changing the balance from $500 to $400. The accounts table now actually contains two rows for account 2: a row with a balance of $500 which was marked as deleted by transaction 13, and a row with a balance of $400 which was created by transaction 13
2.2 Visibility rules for observing a consistent snapshot
When a transaction reads from the database, transaction IDs are used to decide which objects it can see and which are invisible. By carefully defining visibility rules, the database can present a consistent snapshot of the database to the application. This works as follows:
At the start of each transaction, the database makes a list of all the other transactions that are in progress (not yet committed or aborted) at that time. Any writes that those transactions have made are ignored, even if the transactions subsequently commit
Any writes made by aborted transactions are ignored
Any writes made by transactions with a later transaction ID (i.e., which started after the current transaction started) are ignored, regardless of whether those transactions have committed
All other writes are visible to the application’s queries
Put another way, an object is visible if both of the following conditions are true:
At the time when the reader’s transaction started, the transaction that created the object had already committed
The object is not marked for deletion, or if it is, the transaction that requested deletion had not yet committed at the time when the reader’s transaction started
2.3 Indexes and snapshot isolation
How do indexes work in a multi-version database? One option is to have the index simply point to all versions of an object and require an index query to filter out any object versions that are not visible to the current transaction. When garbage collection removes old object versions that are no longer visible to any transaction, the corresponding index entries can also be removed
In practice, many implementation details determine the performance of MVCC. For example, PostgreSQL has optimizations for avoiding index updates if different versions of the same object can fit on the same page
Another approach is used in CouchDB, Datomic, and LMDB. Although they also use B-trees, they use an append-only/copy-on-write variant that does not overwrite pages of the tree when they are updated, but instead creates a new copy of each modified page. Parent pages, up to the root of the tree, are copied and updated to point to the new versions of their child pages. Any pages that are not affected by a write do not need to be copied, and remain immutable
With append-only B-trees, every write transaction (or batch of transactions) creates a new B-tree root, and a particular root is a consistent snapshot of the database at the point in time when it was created. There is no need to filter out objects based on transaction IDs because subsequent writes cannot modify an existing B-tree; they can only create new tree roots. However, this approach also requires a background process for compaction and garbage collection
2.4 Repeatable read and naming confusion
Snapshot isolation is a useful isolation level, especially for read-only transactions. However, many databases that implement it call it by different names. In Oracle it is called serializable, and in PostgreSQL and MySQL it is called repeatable read
The reason for this naming confusion is that the SQL standard doesn’t have the concept of snapshot isolation, because the standard is based on System R’s 1975 definition of isolation levels and snapshot isolation hadn’t yet been invented then
Instead, it defines repeatable read, which looks superficially similar to snapshot isolation. PostgreSQL and MySQL call their snapshot isolation level repeatable read because it meets the requirements of the standard, and so they can claim standards compliance
Unfortunately, the SQL standard’s definition of isolation levels is flawed—it is ambiguous, imprecise, and not as implementation-independent as a standard should be. Even though several databases implement repeatable read, there are big differences in the guarantees they actually provide, despite being ostensibly standardized. There has been a formal definition of repeatable read in the research literature, but most implementations don’t satisfy that formal definition. And to top it off, IBM DB2 uses “repeatable read” to refer to serializability. As a result, nobody really knows what repeatable read means