0. Overview
- Single-leader and multi-leader replication are based on the idea that a client sends a write request to the leader, and the database system takes care of copying that write to the other replicas. A leader determines the order in which writes should be processed, and followers apply the leader’s writes in the same order
- Some data storage systems take a different approach, abandoning the concept of a leader and allowing any replica to directly accept writes from clients. In some leaderless implementations, the client directly sends its writes to several replicas, while in others, a coordinator node does this on behalf of the client. However, unlike a leader database, that coordinator does not enforce a particular ordering of writes, this difference in design has profound consequences for the way the database is used
- Some of the earliest replicated data systems were leaderless, but the idea was mostly forgotten during the era of dominance of relational databases. It once again became a fashionable architecture for databases after Amazon used it for its in-house Dynamo system. Riak, Cassandra, and Voldemort are open source datastores with leaderless replication models inspired by Dynamo, so this kind of database is also known as Dynamo-style
1. Writing to the Database When a Node Is Down
- In a leaderless configuration, failover does not exist. For example, the client sends the write to all three replicas in parallel, and the two available replicas accept the write but the unavailable replica misses it. Let’s say that it’s sufficient for two out of three replicas to acknowledge the write: after client has received two ok responses, we consider the write to be successful
- If the unavailable node comes back online, and clients start reading from it, they may get stale values as responses. To solve that problem, when a client reads from the database, it doesn’t just send its request to one replica: read requests are also sent to several nodes in parallel. The client may get different responses from different nodes, version numbers are used to determine which value is newer
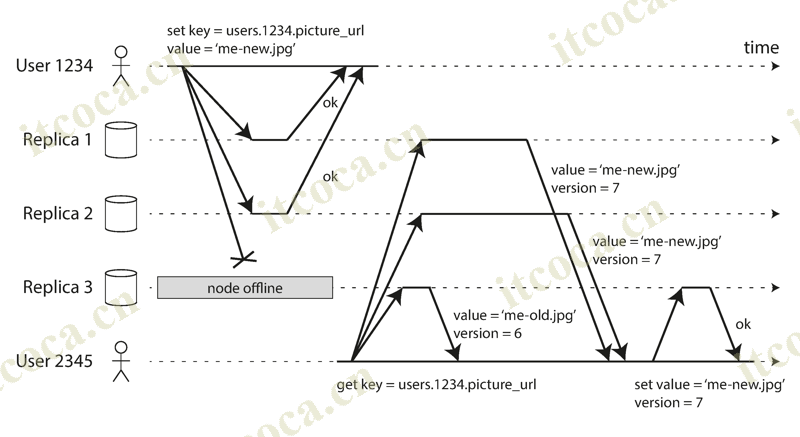
1.1. Read repair and anti-entropy
- The replication scheme should ensure that eventually all the data is copied to every replica. Two mechanisms are often used in Dynamo-style datastores:
- Read repair: When a client makes a read from several nodes in parallel, it can detect any stale responses. The client can writes the newer value back to the replica which has stale value. This approach works well for values that are frequently read
- Anti-entropy process: Some datastores have a background process that constantly looks for differences in the data between replicas and copies any missing data from one replica to another. Unlike the replication log in leader-based replication, this anti-entropy process does not copy writes in any particular order, and there may be a significant delay before data is copied
- Not all systems implement both of these. Note that without an anti-entropy process, values that are rarely read may be missing from some replicas and thus have reduced durability
1.2. Quorums for reading and writing
- If we know that every successful write is guaranteed to be present on at least two out of three replicas, that means at most one replica can be stale. Thus, if we read from at least two replicas, we can be sure that at least one of the two is up to date
- More generally, if there are
nreplicas, every write must be confirmed bywnodes to be considered successful, and we must query at leastrnodes for each read (In the example, n = 3, w = 2, r = 2). As long asw + r > n, we expect to get an up-to-date value when reading, because at least one of the r nodes we’re reading from must be up to date. Reads and writes that obey these r and w values are called (strict) quorum reads and writes - In Dynamo-style databases, the parameters n, w, and r are typically configurable. A common choice is to make n an odd number (typically 3 or 5) and to set w = r = (n + 1) / 2 (rounded up), because that ensures w + r > n while still tolerating up to n/2 node failures. However, you can vary the numbers as you see fit. For example, a workload with few writes and many reads may benefit from setting w = n and r = 1. This makes reads faster, but has the disadvantage that just one failed node causes all database writes to fail. You may also set w and r to smaller numbers, so that w + r ≤ n. In this case, reads and writes will still be sent to n nodes, but you are more likely to read stale values. On the upside, this configuration allows lower latency and higher availability
- The quorum condition, w + r > n, allows the system to tolerate unavailable nodes as follows:
- If w < n, we can still process writes if a node is unavailable
- If r < n, we can still process reads if a node is unavailable
- With n = 3, w = 2, r = 2 we can tolerate one unavailable node
- With n = 5, w = 3, r = 3 we can tolerate two unavailable nodes
- Normally, reads and writes are always sent to all n replicas in parallel. The parameters w and r determine how many nodes we wait for
- If fewer than the required w or r nodes are available, writes or reads return an error
2. Limitations of Quorum Consistency
- Even with w + r > n, there are likely to be edge cases where stale values are returned. These depend on the implementation, but possible scenarios include:
- If a sloppy quorum is used, the w writes may end up on different nodes than the r reads, so there is no longer a guaranteed overlap between the r nodes and the w nodes
- If two writes occur concurrently, it is not clear which one happened first. In this case, the only safe solution is to merge the concurrent writes. If a winner is picked based on a timestamp (LWW), writes can be lost due to clock skew
- If a write happens concurrently with a read, the write may be reflected on only some of the replicas. In this case, it’s undetermined whether the read returns the old or the new value
- If a write on fewer than w replicas, it is not rolled back on the replicas where it succeeded. This means that if a write was reported as failed, subsequent reads may or may not return the value from that write
- If a node carrying a new value fails, and its data is restored from a replica carrying an old value, the number of replicas storing the new value may fall below w, breaking the quorum condition
- Even if everything is working correctly, there are edge cases in which you can get unlucky with the timing
- Thus, although quorums appear to guarantee that a read returns the latest written value, in practice it is not so simple. Dynamo-style databases are generally optimized for use cases that can tolerate eventual consistency. The parameters w and r allow you to adjust the probability of stale values being read, but it’s wise to not take them as absolute guarantees
- In particular, you usually do not get the guarantees (reading your writes, monotonic reads, or consistent prefix reads), so the previously mentioned anomalies can occur in applications. Stronger guarantees generally require transactions or consensus
2.1. Monitoring staleness
- From an operational perspective, it’s important to monitor whether your databases are returning up-to-date results. Even if your application can tolerate stale reads, you need to be aware of the health of your replication. If it falls behind significantly, it should alert you so that you can investigate the cause
- For leader-based replication, the database typically exposes metrics for the replication lag, which you can feed into a monitoring system. This is possible because writes are applied to the leader and to followers in the same order, and each node has a position in the replication log (the number of writes it has applied locally). By subtracting a follower’s current position from the leader’s current position, you can measure the amount of replication lag
- However, in systems with leaderless replication, there is no fixed order in which writes are applied, which makes monitoring more difficult. Moreover, if the database only uses read repair (no anti-entropy), there is no limit to how old a value might be
- There has been some research on measuring replica staleness in databases with leaderless replication and predicting the expected percentage of stale reads depending on the parameters n, w, and r. This is unfortunately not yet common practice, but it would be good to include staleness measurements in the standard set of metrics for databases. Eventual consistency is a deliberately vague guarantee, but for operability it’s important to be able to quantify “eventual”
2.2. Sloppy Quorums and Hinted Handoff
- There may be more than n nodes in the cluster, but any given value is stored only on n nodes. This allows the dataset to be partitioned, supporting datasets that are larger than you can fit on one node
- Databases with appropriately configured quorums can tolerate the failure of individual nodes without the need for failover, they can also tolerate individual nodes going slow. These characteristics make databases with leaderless replication appealing for use cases that require high availability and low latency, and that can tolerate occasional stale reads
- However, quorums are not as fault-tolerant as they could be. A network interruption can easily cut off a client from a large number of database nodes, so the client can no longer reach a quorum. In a large cluster (with significantly more than n nodes) it’s likely that the client can connect to some database nodes during the network interruption, just not to the nodes that it needs to assemble a quorum for a particular value. In that case, database designers face a trade-off:
- Is it better to return errors to all requests for which we cannot reach a quorum of w or r nodes?
- Or should we accept writes anyway, and write them to some nodes that are reachable but aren’t among the n nodes on which the value usually lives?
- The latter is known as a sloppy quorum: writes and reads still require w and r successful responses, but those may include nodes that are not among the designated n “home” nodes for a value. Once the network interruption is fixed, any writes that one node temporarily accepted on behalf of another node are sent to the appropriate “home” nodes. This is called hinted handoff
- Sloppy quorums are optional in all common Dynamo implementations, it’s particularly useful for increasing write availability: as long as any w nodes are available, the database can accept writes. However, this means that even when w + r > n, you cannot be sure to read the latest value for a key until the hinted handoff has completed
2.3. Multi-datacenter operation
- Leaderless replication is also suitable for multi-datacenter operation, since it is designed to tolerate conflicting concurrent writes, network interruptions, and latency spikes
- Cassandra and Voldemort implement their multi-datacenter support within the normal leaderless model: the number of replicas n includes nodes in all datacenters, and in the configuration you can specify how many of the n replicas you want to have in each datacenter. Each write from a client is sent to all replicas, regardless of datacenter, but the client usually only waits for acknowledgment from a quorum of nodes within its local datacenter so that it is unaffected by delays and interruptions on the cross-datacenter link. The higher-latency writes to other datacenters are often configured to happen asynchronously, although there is some flexibility in the configuration
- Riak keeps all communication between clients and database nodes local to one datacenter, so n describes the number of replicas within one datacenter. Cross-datacenter replication between database clusters happens asynchronously in the background, in a style that is similar to multi-leader replication
3. Detecting Concurrent Writes
- Dynamo-style databases allow several clients to concurrently write to the same key, which means that conflicts will occur even if strict quorums are used. The situation is similar to multi-leader replication, although in Dynamo-style databases conflicts can also arise during read repair or hinted handoff
- Events may arrive in a different order at different nodes. In order to become eventually consistent, the replicas should converge toward the same value. One might hope that replicated databases would handle this automatically, but unfortunately most implementations are quite poor: if you want to avoid losing data, you—the application developer—need to know a lot about the internals of your database’s conflict handling
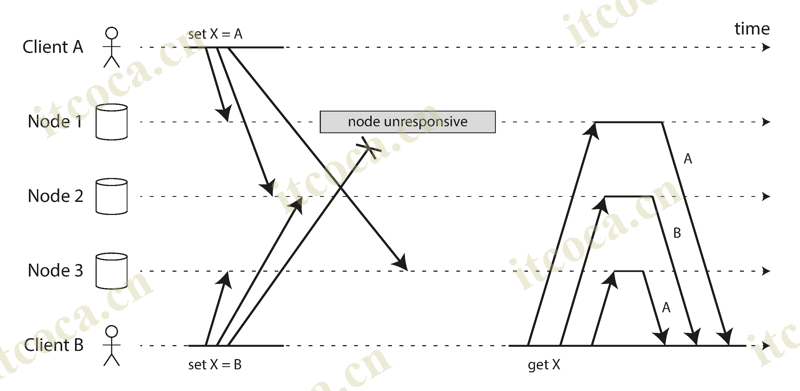
3.1. Last write wins (discarding concurrent writes)
- One approach for achieving eventual convergence is to declare that each replica need only store the most “recent” value and allow “older” values to be overwritten and discarded. Even though the concurrent writes don’t have a natural ordering, we can force an arbitrary order on them
- For example, we can attach a timestamp to each write, pick the biggest timestamp as the most “recent” and discard any writes with an earlier timestamp. This conflict resolution algorithm, called last write wins (LWW). LWW achieves the goal of eventual convergence, but at the cost of durability: only one of the writes will survive and the others will be silently discarded, even if they were all reported as successful to the client. Moreover, LWW may even drop writes that are not concurrent
- There are some situations, such as caching, in which lost writes are perhaps acceptable. If losing data is not acceptable, LWW is a poor choice for conflict resolution. The only safe way of using a database with LWW is to ensure that a key is only written once and thereafter treated as immutable, thus avoiding any concurrent updates to the same key. For example, a recommended way of using Cassandra is to use a UUID as the key, thus giving each write operation a unique key
3.2. The “happens-before” relationship and concurrency
- An operation A happens before another operation B if B knows about A, or depends on A, or builds upon A in some way. Whether one operation happens before another operation is the key to defining what concurrency means. In fact, we can simply say that two operations are concurrent if neither happens before the other
- What we need is an algorithm to tell us whether two operations are concurrent or not. If one operation happened before another, the later operation should overwrite the earlier operation, but if the operations are concurrent, we have a conflict that needs to be resolved
Concurrency, Time, and Relativity
- It may seem that two operations should be called concurrent if they occur “at the same time”—but in fact, it is not important whether they literally overlap in time. Because of problems with clocks in distributed systems, it is actually quite difficult to tell whether two things happened at exactly the same time
- For defining concurrency, exact time doesn’t matter: we simply call two operations concurrent if they are both unaware of each other, regardless of the physical time at which they occurred. People sometimes make a connection between this principle and the special theory of relativity in physics, which introduced the idea that information cannot travel faster than the speed of light. Consequently, two events that occur some distance apart cannot possibly affect each other if the time between the events is shorter than the time it takes light to travel the distance between them
- In computer systems, two operations might be concurrent even though the speed of light would in principle have allowed one operation to affect the other. For example, if the network was slow or interrupted at the time, two operations can occur some time apart and still be concurrent, because the network problems prevented one operation from being able to know about the other
3.3. Capturing the happens-before relationship
- This example shows two clients concurrently adding items to the same shopping cart, it use algorithm that determines whether two operations are concurrent, or whether one happened before another
- Client 1 adds milk to the cart. This is the first write to that key, so the server stores it and assigns it version 1. The server also echoes the value back to the client, along with the version number
- Client 2 adds eggs to the cart, not knowing that client 1 concurrently added milk. The server assigns version 2 to this write, and stores eggs and milk as two separate values. It then returns both values to the client, along with the version number of 2
- Client 1 adds flour to the cart, it thinks the current cart contents should be [milk, flour]. It sends this value to the server, along with the version number 1. The server can tell from the version number that the write of [milk, flour] supersedes the prior value of [milk] but that it is concurrent with [eggs]. Thus, the server assigns version 3 to [milk, flour], overwrites the version 1 value [milk], but keeps the version 2 value [eggs] and returns both remaining values to the client
- Client 2 adds ham to the cart. It previously received [milk] and [eggs] from the server in the last response, so the client now merges those values and adds ham to form a new value [eggs, milk, ham]. It sends that value to the server, along with the version number 2. The server detects that version 2 overwrites [eggs] but is concurrent with [milk, flour], so the two remaining values are [milk, flour] with version 3, and [eggs, milk, ham] with version 4
- Client 1 adds bacon to the cart. It previously received [milk, flour] and [eggs] from the server at version 3, so it merges those, adds bacon, and sends the final value [milk, flour, eggs, bacon] to the server, along with the version number 3. This overwrites [milk, flour] but is concurrent with [eggs, milk, ham], so the server keeps those two concurrent values
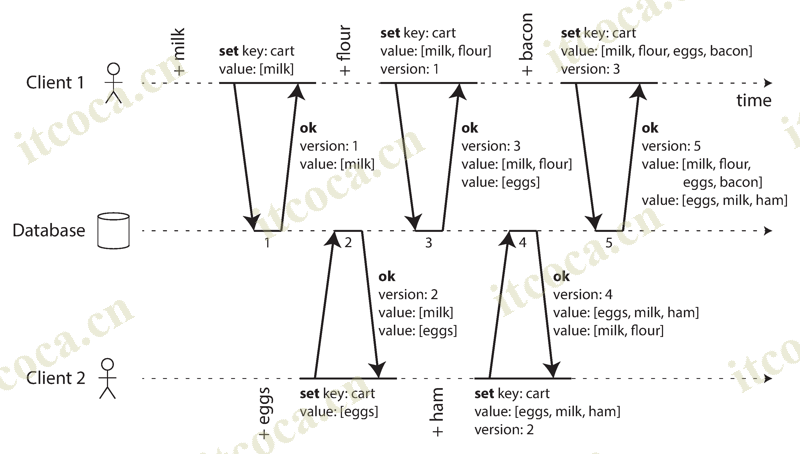
- In this example, the clients are never fully up to date with the data on the server, since there is always another operation going on concurrently. But the later operation knew about or depended on the earlier one, old versions of the value do get overwritten eventually, and no writes are lost
- The server can determine whether two operations are concurrent by looking at the version numbers. The algorithm works as follows:
- The server maintains a version number for every key, increments the version number every time that key is written, and stores the new version number along with the value written
- When a client reads a key, the server returns all values that have not been overwritten, as well as the latest version number. A client must read a key before writing
- When a client writes a key, it must include the version number from the prior read, and it must merge together all values that it received in the prior read (The response from a write request can be like a read, returning all current values)
- When the server receives a write with a particular version number, it can overwrite all values with that version number or below (since it knows that they have been merged into the new value), but it must keep all values with a higher version number (because those values are concurrent with the incoming write)
- When a write includes the version number from a prior read, that tells us which previous state the write is based on. If you make a write without including a version number, it is concurrent with all other writes, so it will not overwrite anything—it will just be returned as one of the values on subsequent reads
3.4. Merging concurrently written values
- This algorithm ensures that no data is silently dropped, but it unfortunately requires that the clients do some extra work: if several operations happen concurrently, clients have to clean up afterward by merging the concurrently written values (Riak calls these concurrent values siblings)
- Merging sibling values is essentially the same problem as conflict resolution in multileader replication. But we can’t just pick one of the values based on a version number or timestamp. With the example of a shopping cart, a reasonable approach to merging siblings is to just take the union. However, if you want to allow people to also remove things from their carts, and not just add things, then taking the union of siblings may not yield the right result. To prevent this problem, an item cannot simply be deleted from the database when it is removed; instead, the system must leave a marker with an appropriate version number to indicate that the item has been removed when merging siblings. Such a deletion marker is known as a tombstone
- As merging siblings in application code is complex and error-prone, there are some efforts to design data structures that can perform this merging automatically. For example, Riak’s datatype support uses a family of data structures called CRDTs that can automatically merge siblings in sensible ways, including preserving deletions
3.5. Version vectors
- The example uses a single version number to capture dependencies between operations, but that is not sufficient when there are multiple replicas accepting writes concurrently. Instead, we need to use a version number per replica as well as per key. Each replica increments its own version number when processing a write, and also keeps track of the version numbers it has seen from each of the other replicas. This information indicates which values to overwrite and which values to keep as siblings
- The collection of version numbers from all the replicas is called a version vector. Like the version numbers in example, version vectors are sent from the database replicas to clients when values are read, and need to be sent back to the database when a value is subsequently written. Also, the application may need to merge siblings. The version vector structure ensures that it is safe to read from one replica and subsequently write back to another replica. Doing so may result in siblings being created, but no data is lost as long as siblings are merged correctly
References
- Designing Data-Intensive Application