一、转换算子(Transformation)
- 数据源读入数据之后,可以使用各种转换算子,将一个或多个 DataStream 转换为新的 DataStream
1. map
- 将数据流中的数据进行转换,形成新的数据流。简单来说就是“一一映射”,消费一个元素就产出一个元素
- 只需要基于 DataStream 调用 map() 方法就可以进行转换处理。方法需要传入的参数是接口
MapFunction的实现,返回值类型还是 DataStream,不过泛型(流中的元素类型)可能改变
1 | stream.map(new MapFunction<InType, OutType>() { |
2. filter
- 对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉
- 进行 filter 转换之后的新数据流的数据类型与原数据流是相同的,filter 转换需要传入的参数需要实现
FilterFunction接口,而 FilterFunction 内要实现 filter() 方法,返回布尔类型
1 | stream.filter(new FilterFunction<InType>() { |
3. flatMap
- 又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生 0 到多个元素
1 | stream.map(new FlatMapFunction<InType, OutType>() { |
二、聚合算子(Aggregation)
- 聚合:计算的结果不仅依赖当前数据,还跟之前的数据有关,相当于要把所有数据聚在一起进行汇总合并
1. 按键分区(keyBy)
- Flink 的 DataStream 没有直接进行全局聚合的 API(要先分区,再并行处理)。分区的操作就是通过 keyBy 来完成的
- keyBy 是聚合前必须要用到的一个算子,通过指定 key,将一条流从逻辑上划分成不同的分区(partitions)。具有相同的 key 的数据,都将被发往同一个分区,一个分区也可以有多组相同 key 的数据。分区其实就是并行处理的子任务
- 在内部,是通过计算 key 的哈希值(hash code)对分区数进行取模运算来实现分区的。因此如果 key 是 POJO 的话,必须要重写其 hashCode() 方法
- keyBy() 方法需要传入一个键选择器(KeySelector),用于从数据中提取 key
- keyBy 得到的结果不再是 DataStream,而是 KeyedStream。KeyedStream 可以认为是“分区流”或者“键控流”,它是对 DataStream 按照 key 的一个逻辑分区,只有基于它才可以做后续的聚合操作(如 sum、reduce)
- KeyedStream 也继承自 DataStream,所以基于它的操作也都归属于 DataStream API。但它跟之前的转换操作得到的 SingleOutputStreamOperator 不同,因为 keyBy 只是一个对流的分区操作,并不是一个转换算子,且不能设置并行度
1 | KeyedStream<InType, KeyType> keyedStream = stream.keyBy(new KeySelector<InType, KeyType>() { |
2. 简单聚合(sum/min/max/minBy/maxBy)
- 基于 KeyedStream 可以进行聚合操作(对同一个 key 的数据进行聚合),Flink 内置实现了一些基本的聚合 API:
sum():在输入流上,对指定的字段叠加求和min():在输入流上,对指定的字段求最小值max():在输入流上,对指定的字段求最大值minBy():与 min() 类似。不同的是,min() 的非比较字段保留第一次的值;而 minBy() 会取整条数据maxBy():与 max() 类似。区别与 min()/minBy() 一致
- 进行简单聚合操作后返回的类型是 SingleOutputStreamOperator,也就是从 KeyedStream 又转换成了常规的 DataStream,且元素的数据类型保持不变
- 聚合算子会为每一个 key 保存一个聚合的值,在 Flink 中把它叫作“状态”(state)。每当有一个新的数据输入,算子就会更新保存的聚合结果,并发送一个带有更新后聚合值的事件到下游算子。对于无界流来说,这些状态是永远不会被清除的,所以使用聚合算子时,应该只用在含有有限个 key 的数据流上
- 这些聚合方法调用时,需要指定聚合的字段。指定字段的方式有两种:指定位置或指定名称
- POJO 类型只能指定字段名称;元组类型字段的名称是以 f0、f1、… 来命名的
1 | keyedStream.max("age"); |
3. 归约聚合(reduce)
- reduce 可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算
- 调用 reduce 方法需要传入一个实现了 ReduceFunction 接口的参数
1 | keyedStream.reduce(new ReduceFunction<InType>(){ |
三、分区算子(Partitioning)
- 常见的物理分区策略有:随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)
1. 随机分区(shuffle)
- 随机分区服从均匀分布(uniform distribution),把流中的数据随机打乱,均匀地传递到下游任务分区。因为是完全随机的,对于同样的输入数据,每次执行得到的结果也不会相同
1 | // random.nextInt(下游算子并行度); |
2. 轮询分区(rebalance)
- 轮询按照先后顺序将数据做依次分发。如果是数据源倾斜的场景,比如 3 个并行度消费 3 个 Kafka 分区,Source 后调用 rebalance 就可以解决数据源的数据倾斜问题
1 | // nextChannelToSendTo = (nextChannelToSendTo + 1) % 下游算子并行度 |
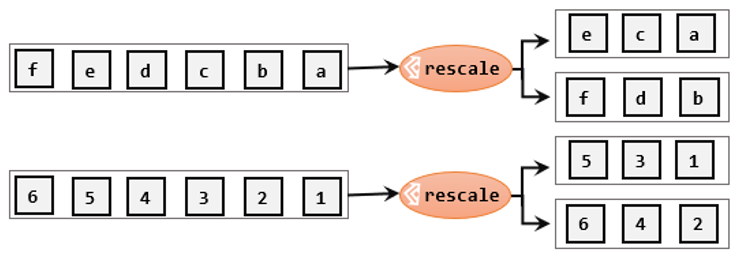
3. 重缩放分区(rescale)
- 重缩放分区和轮询分区非常相似,其底层也是使用 Round-Robin 算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中。rescale 的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌
1 | env.setParallelism(2); |
4. 广播(broadcast)
- 将输入数据复制并发送到下游算子的所有并行任务中去。经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理
1 | env.setParallelism(2); |
5. 全局分区(global)
- 会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。相当于强行让下游任务并行度变成了 1
1 | env.setParallelism(2); |
6. 其他分区器
KeyGroupStreamPartitioner:keyByForwardPartitioner:one-to-one
7. 自定义分区
- 通过使用
partitionCustom()方法来自定义分区策略
1 | public class MyPartitioner implements Partitioner<String> { |
四、分流
- 分流就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个 DataStream,定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里
1. 筛选(filter)
- 针对同一条流多次独立调用 filter() 方法进行筛选,就可以得到多个拆分后的流
- 缺点:同一个数据需要处理多遍
1 | SingleOutputStreamOperator<Integer> outStream1 = stream.filter(x -> x % 2 == 0); |
2. 侧输出流(SideOutput)
- 侧输出流需要调用上下文的
ctx.output()方法,并指定输出标记(OutputTag)
1 | OutputTag<InType> tag1 = new OutputTag<>("stream1", Types.POJO(InType.class)); |
五、合流
- 实际应用中,经常会遇到来源不同的多条流,需要将它们的数据进行联合处理
1. 联合(union)
- 联合操作要求流中的数据类型必须相同,合并之后的新流会包括所有流中的元素
- 调用
DataStream.union()方法,传入其他 DataStream 作为参数,得到的依然是一个 DataStream
1 | stream1.union(stream2, stream3, ...) |
2. 连接(connect)
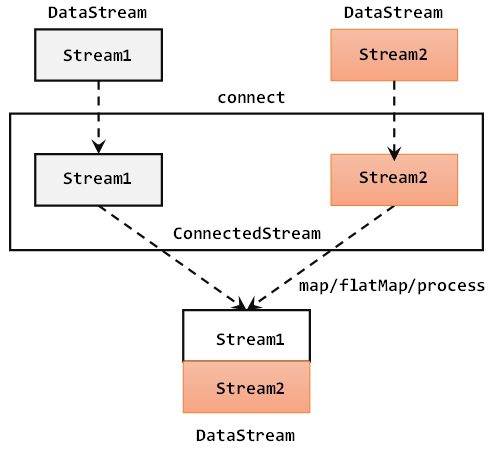
- 连接操作允许流的数据类型不同,但一次只能连接两条流
- 连接得到的不是 DataStream,而是 ConnectedStreams,可以看成是两个流形式上的统一,被放在了同一个流中;事实上内部仍保持各自的数据形式不变,彼此是相互独立的
- 要想得到新的 DataStream,需要进行 co-process 同处理转换操作(
map/flatMap/process),说明对不同来源、不同类型的数据,分别怎样进行转换,得到统一的输出类型
1 | DataStreamSource<Integer> stream1 = env.fromElements(1, 2, 3); |
- ConnectedStreams 可以调用 keyBy() 进行按键分区的操作,得到的还是一个 ConnectedStreams。把两条流中 key 相同的数据放到了同一个分区,然后针对不同来源的流再做各自处理
1 | // 传入两条流中各自的键选择器 |
六、用户自定义函数
- 用户自定义函数(User-Defined Function,UDF),即用户可以根据自身需求,重新实现算子的逻辑。主要分为:函数类、匿名函数类、富函数类
- Flink 暴露了所有 UDF 函数的接口,具体实现方式为接口或者抽象类,例如 MapFunction、FilterFunction、ReduceFunction 等。用户可以自定义一个函数类,实现对应的接口
- 所有的 Flink 函数类都有其 Rich 版本,富函数类一般是以抽象类的形式出现的,例如 RichMapFunction、RichFilterFunction、RichReduceFunction 等
- 与常规函数类的不同主要在于,富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能
1 | source.map(new RichMapFunction<String, Integer>() { |