一、为 Pod 中的容器申请资源
- 创建 Pod 时可以指定容器对 CPU 和内存的资源请求量(requests)和限制量(limits)
- 每个容器单独指定
- Pod 对资源的请求量和限制量是其包含容器的请求量和限制量之和
1. 创建包含资源 requests 的 Pod
1 | apiVersion: v1 |
- 容器需要 1/5 核的 CPU 才能正常运行。如果不指定 CPU requests,最坏的情况下容器进程会分不到 CPU 时间
1 | $ kubectl exec -it requests-pod top |
- dd 命令会消耗尽可能多的 CPU,但它在容器内是单线程运行,所以只能跑满一个核,而节点有两个核,因此 50%
- 容器实际使用量超过了资源申请量,因为 requests 不会限制容器可以使用的 CPU 数量
在容器内看到的始终是节点的内存和 CPU,而非容器本身的
对于 Java 程序,如果不使用
-Xmx指定虚拟机最大堆大小,JVM 会将其设置为主机总物理内存的百分值,如果部署在大内存的节点,JVM 将很容易超过配置的内存 limits。另外也需考虑 off-heap 内存大小一些程序通过系统 CPU 核数来决定启动工作线程的数量,如果部署在多核节点,程序将启动大量线程,线程会争夺有限的 CPU 时间,同时线程一般需要额外的内存资源,导致内存用量增加
可以使用 Downward API 将 CPU 限额传递至容器并使用这个值。也可以通过 cgroup 系统直接获取配置的 CPU 限制(/sys/fs/cgroup/cpu/{cpu.cfs_quota_us, cpu.cfs_period_us})
2. 资源 requests 如何影响调度
- requests 指定了 Pod 对资源需求的最小值,调度器将在 Pod 调度时用到该信息。每个节点的资源量是一定的,调度器只考虑未分配资源满足 Pod 需求量的节点
- 调度器在调度时并不关注各类资源在当前时刻的实际使用量,而只关心该节点上部署的所有 Pod 的资源申请量之和
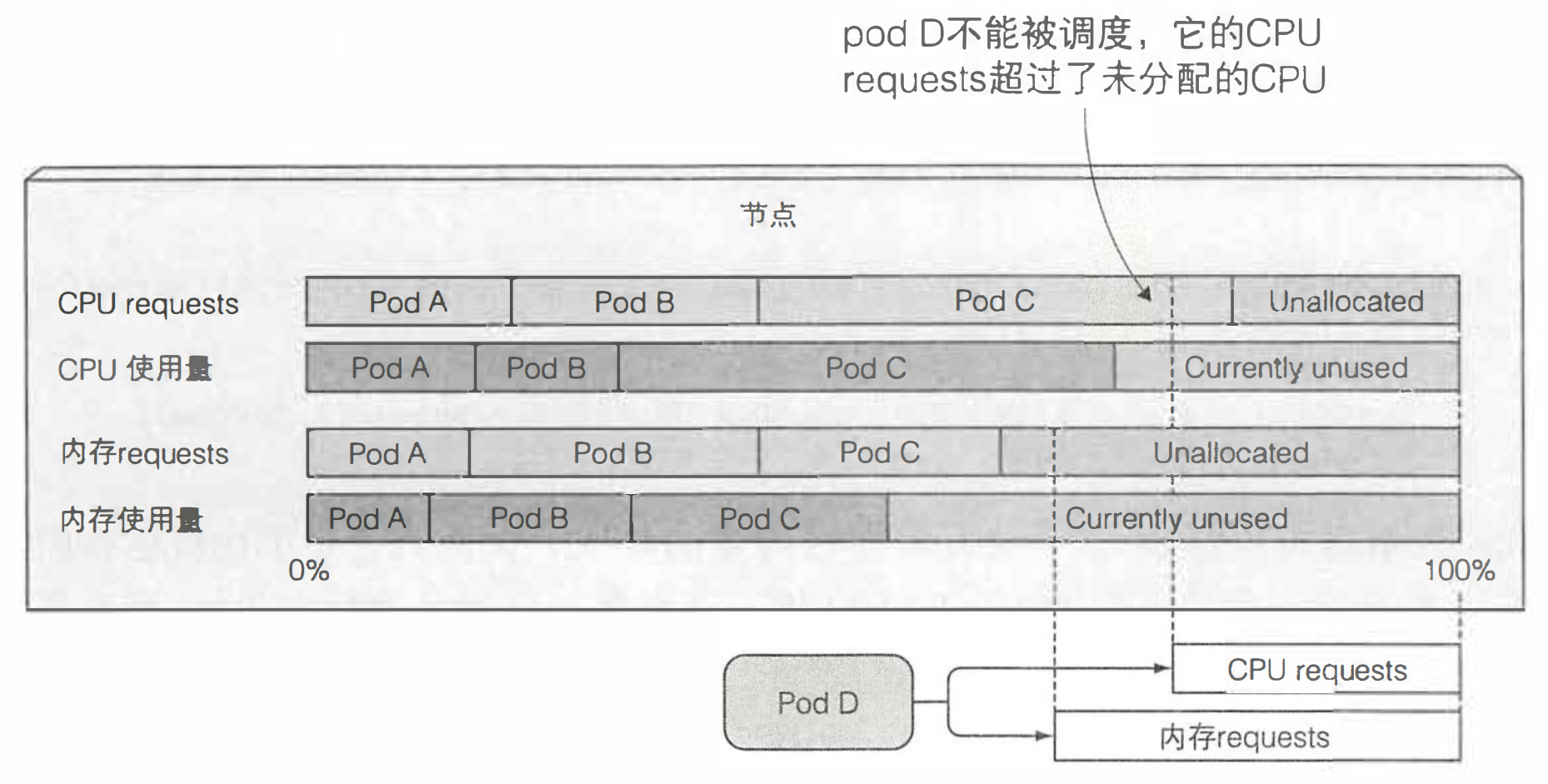
- 上图的 Pod D 无法调度到该节点上,因为其 CPU 申请量大于节点的未分配量(与实际使用量无关)
- 调度器首先对节点列表进行过滤,排除不满足需求的节点,然后根据配置的优先级函数对其余节点排序。其中有两个基于资源请求量的优先级函数:
LeastRequestedPriority(优先调度到请求资源少的节点)、MostRequestedPriority(优先调度到请求资源多的节点)。调度器只能配置一种优先级函数 - 查看节点资源总量(Kubelet 向 API 服务器报告的数据)
1 | $ kubectl describe node |
- 测试超过资源总量
1 | $ kubectl run requests-pod-2 --image=busybox --restart Never --requests='cpu=1800m,memory=20Mi' -- dd if=/dev/zero of=/dev/null |
3. CPU requests 如何影响 CPU 时间分配
- 如果没有定义 limits,Pod 会消耗尽可能多的 CPU
- 假设一个容器能跑满 CPU,另一个容器处于空闲状态,那么前者可以使用整个 CPU 时间。当第二个容器需要 CPU 时间时,第一个容器会被限制
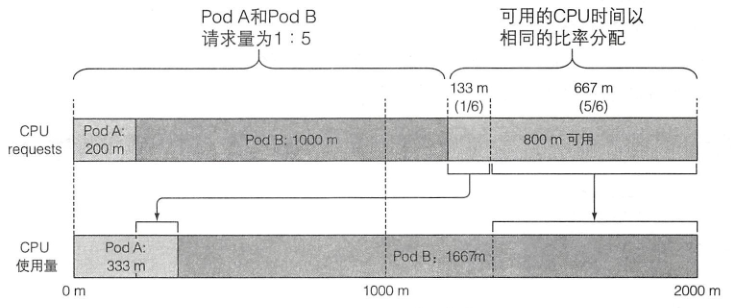
- CPU requests 也决定了未使用的 CPU 时间如何在 Pod 间进行分配
- 假设某 2 核节点共有两个 Pod 全力使用 CPU,一个请求了 200 豪核,一个请求了 1 核,则未使用的 CPU 将按照 1:5 的比例划分给这两个 Pod
4. 定义和申请自定义资源
- Kubernetes 允许用户为节点添加属于自己的自定义资源,同时支持在 Pod 资源 requests 里申请这种资源
- 首先,需要通过将自定义资源加入节点 API 对象的 capacity 属性让 Kubernetes 知道它的存在。这可以通过执行 HTTP 的 PATCH 请求来完成
- 资源名称可以是不以 kubernetes.io 域名开头的任意值,例如 example.org/myresource,数量必须是整数(例如不能设为 100m,因为 0.1 不是整数;但是可以设置为 1000m、2000m,或者简单地设为 1 和 2)。这个值将自动从 capacity 字段复制到 allocatable 字段
- 然后,创建 Pod 时只要在容器 spec 的 resources.requests 字段下,指定自定义资源名称和申请量,调度器就可以确保这个 Pod 只能部署到满足自定义资源申请量的节点,同时每个已部署的 Pod 会减少节点的这类可分配资源数量
- 一个自定义资源的例子就是节点上可用的 GPU 单元数量。如果 Pod 需要使用 GPU,只要简单指定其 requests,调度器就会保证这个 Pod 调度到至少拥有一个未分配 GPU 单元的节点上
二、限制容器的可用资源
- CPU 是一种可压缩资源,意味着可以在不对容器内运行的进程产生不利影响的同时,对其使用量进行限制。而内存是一种不可压缩资源,一旦系统为进程分配了一块内存,这块内存在进程主动释放之前将无法被回收
- 如果不对内存进行限制,节点上的 Pod 可能会用掉所有可用内存,会对节点上其他 Pod 或新调度的 Pod 产生影响
1. 创建包含资源 limits 的 Pod
1 | apiVersion: v1 |
- 如果只指定资源 limits,requests 将被设置为与资源 limits 相同的值
- 资源 limits 不受节点可分配资源量的约束,所有 limits 的总和允许超过节点资源总量
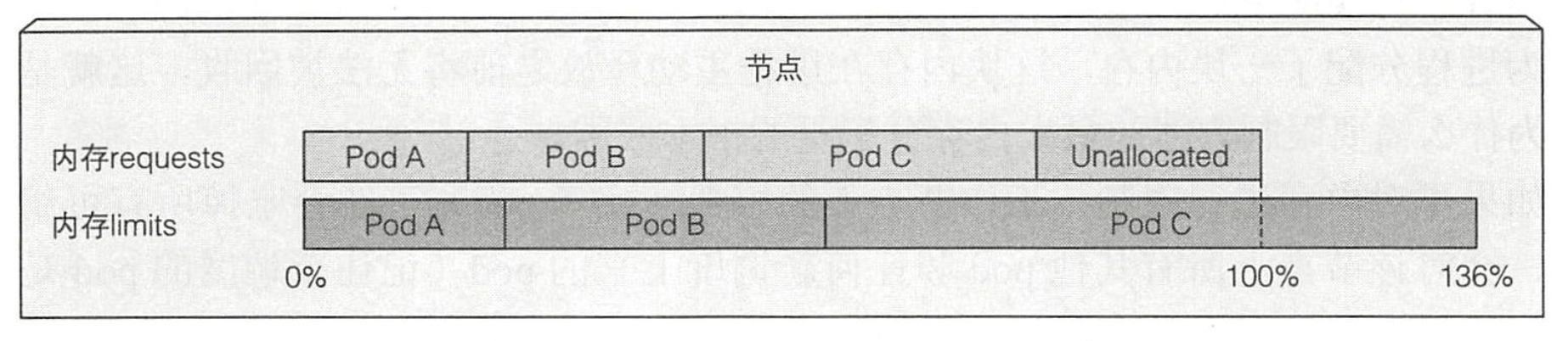
- 如果节点资源使用量超过 100%,一些容器将被杀掉(取决于 QoS 与实际使用量)
2. 超过 limits
- 单个容器尝试使用比自己指定 limits 更多的资源时可能被杀掉
- CPU 是可压缩资源,设置 CPU 限额时,容器只会分不到比限额更多的 CPU 时间
- 内存是不可压缩资源,当进程尝试申请比限额更多的内存时会被杀掉(OOMKilled)。如果 Pod 的重启策略为 Always 或 OnFailure,Pod 会被重启,最终进入 CrashLoopBackOff 状态
CrashLoopBackOff:每次崩溃后,Kubelet 就会增加下次重启之前的间隔时间(0、10、20、40、80、160、…),一旦达到 300s,Kubelet 将以 5min 为时间间隔对容器进行无限重启,直到容器正常或被删除
3. Pod 的 QoS 等级
- Kubernetes 将 Pod 划分为三种 QoS 等级
- BestEffort:没有为任何容器设置任何 requests 和 limits 的 Pod。如果需要为其他 Pod 释放内存,会第一批被杀死
- Burstable:其他所有 Pod
- Guaranteed:为所有容器设置相同 requests 和 limits 的 Pod,CPU 和内存都要设置。只有在系统进程需要内存时才会被杀掉
- 通过
kubectl describe pod或通过 Pod YAML 文件的status.qosClass字段可以查看 QoS 等级 - 对于相同等级的 Pod,系统会优先杀死内存实际使用量占申请量比例更高的 Pod

三、为命名空间中的 Pod 设置默认的 requests 和 limits
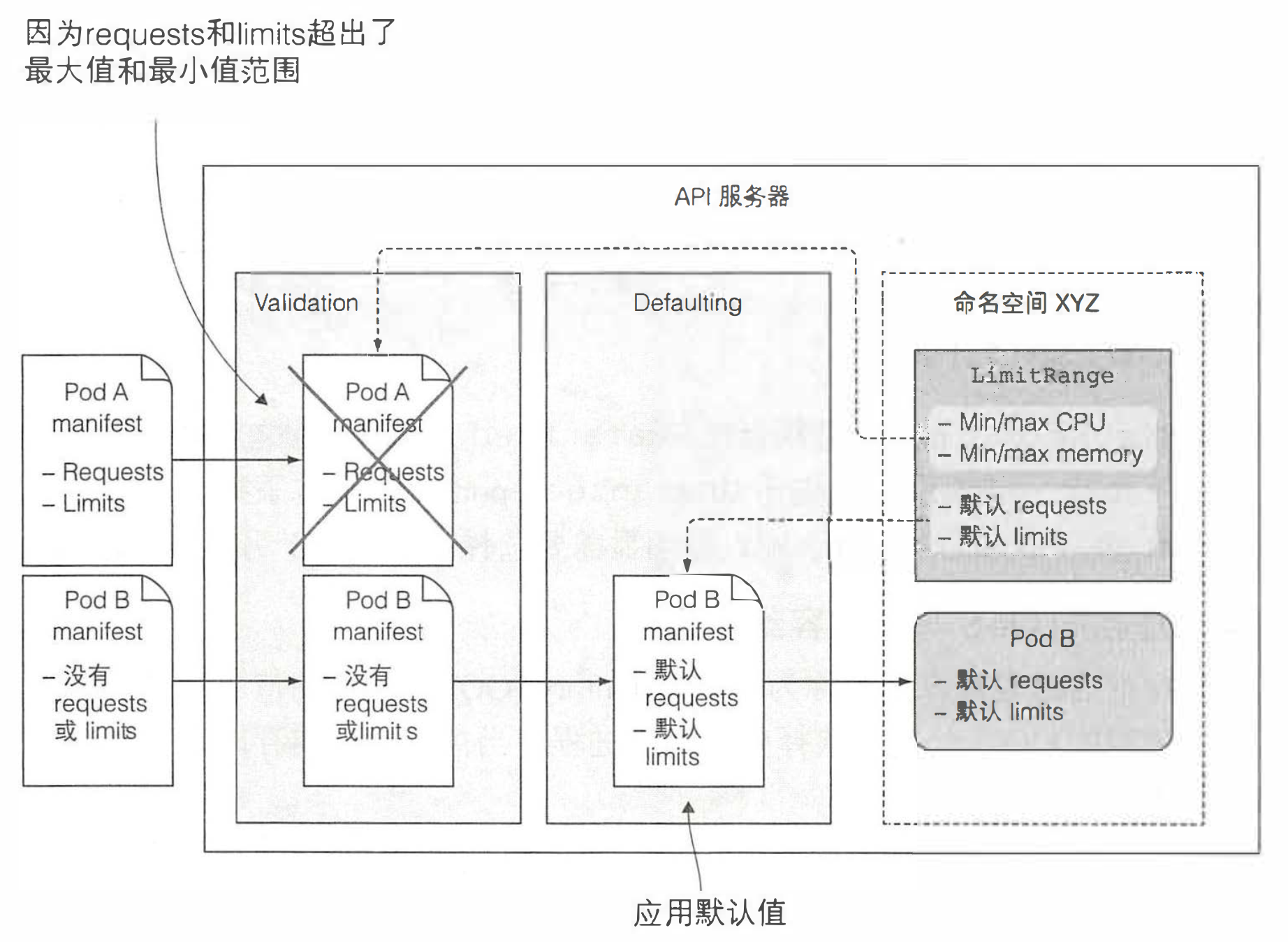
- LimitRange 允许用户为每个命名空间指定能给容器配置的每种资源的最小和最大限额,还支持在没有显式指定资源 requests 时为容器设置默认值
- 用途:以命名空间区分不同团队或不同环境,来限制资源分配;阻止用户创建大于单个节点资源量的 Pod
1 | apiVersion: v1 |
- LimitRange 资源被 LimitRanger 准入控制插件监听。API 服务器收到创建请求时,LimitRanger 插件会对 Pod spec 进行校验,如果校验失败,将直接拒绝(不影响之前创建的资源)
- 多个 LimitRange 对象的限制会在校验合法性时进行合并
四、限制命名空间中的可用资源总量
- LimitRange 资源中的 limits 应用于同一个命名空间中每个独立的 Pod、容器,或者其他类型的对象,但它并不会限制这个命名空间中所有 Pod 可用资源的总量,总量是通过 ResourceQuota 对象指定的
- 资源配额限制了一个命名空间中 Pod 和 PVC 存储最多可以使用的资源总量。同时也可以限制用户允许在该命名空间中创建 Pod、PVC,以及其他 API 对象的数量
1 | apiVersion: v1 |
spec.activeDeadlineSeconds:定义了一个 Pod 从开始尝试停止的时间到其被标记为 Failed 然后真正停止之前,允许其在节点上继续运行的秒数
- 同样的,ResourceQuota 的准入控制插件会检查将要创建的 Pod 是否会导致超过总资源量
- 创建 ResourceQuota 后一般需要创建对应的 LimitRange:如果某个资源配置了某个配额,后续创建 Pod 时需要指定,否则 API 服务器会拒绝创建请求
- 查看命名空间的配额和使用量
1 | $ kubectl describe quota |
五、监控 Pod 的资源使用量
- 通过对容器的资源实际利用率进行监控,以便更好的把握申请的资源量
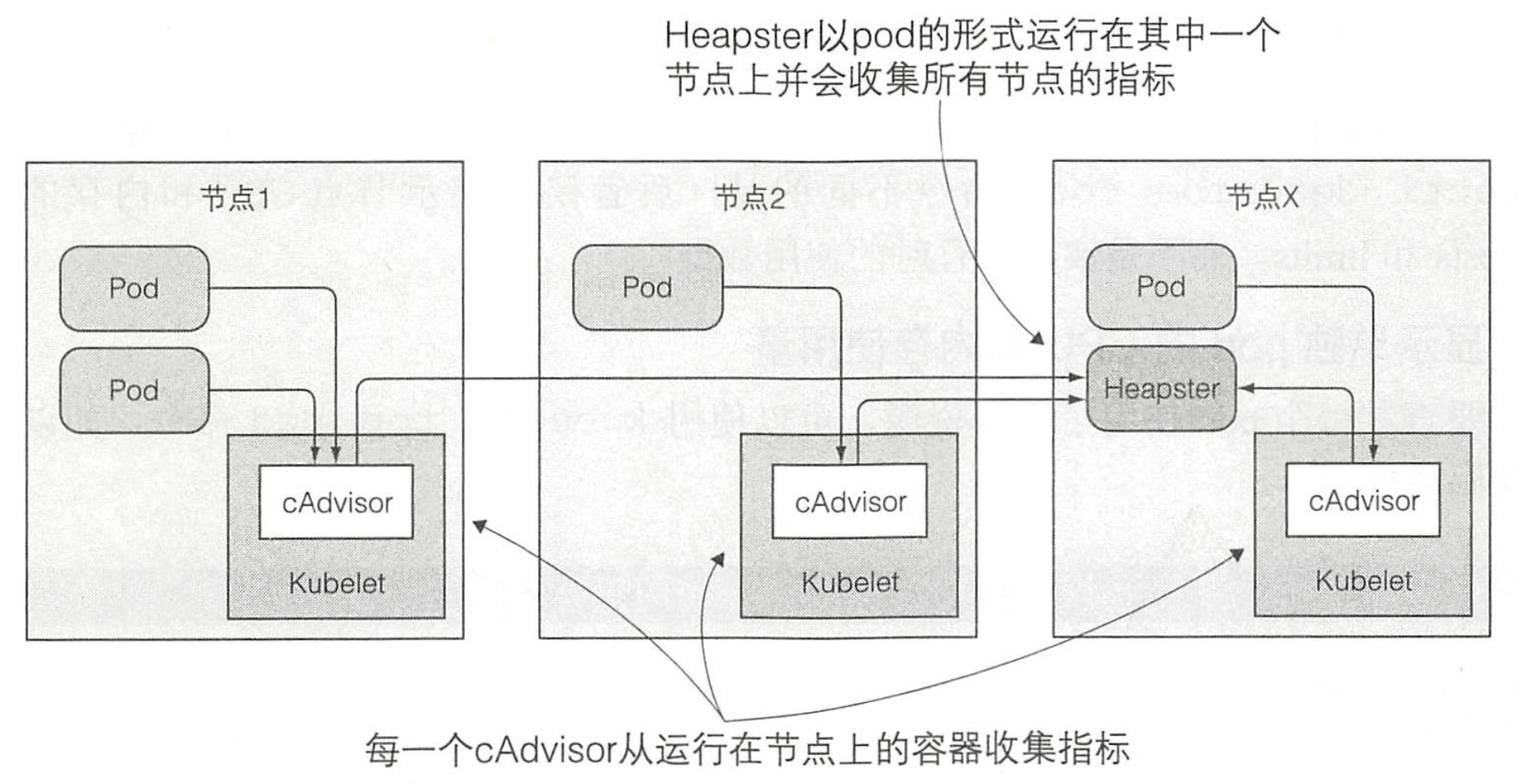
- Kubelet 自身包含一个名为 cAdvisor 的 agent,它会收集整个节点和节点上运行的所有单独容器的资源消耗情况。集中统计整个集群的监控信息需要运行一个叫 Heapster 的附加组件
- Pod 感知不到 cAdvisor 的存在,cAdvisor 也感知不到 Heapster 的存在。Heapster 主动请求所有的 cAdvisor,同时 cAdvisor 无须通过与 Pod 容器内进程通信就可以收集到容器和节点的资源使用数据
- Heapster 通常只保存一个很短时间窗的资源使用量数据,如果需要分析一段时间内的资源使用情况,需要借助额外的工具,如 Prometheus 和 Grafana
- 通常可以通过
kubectl cluster-info命令找到 Grafana 控制台的 URL
- 通常可以通过
1 | # 节点资源使用量 |
- metrics-server:https://github.com/kubernetes-sigs/metrics-server
- 加参数:
--kubelet-insecure-tls
- 加参数: